OpenAI o3 Released: Benchmarks and Comparison to o1
In December 2024, OpenAI announced o3 and o3-mini, with o3 set to launch in early 2025 after completing safety testing.
Today, OpenAI released its newest reasoning model, o3-mini, positioned as a faster and cheaper alternative to the o1 family, optimized for STEM domains, particularly programming, math, and science.

Building on the foundation of OpenAI's o1 models, the o3 family introduces several notable improvements in performance, deeper level of reasoning capabilities, and testing results.
Let's dive into how o3 compares to top models in the market!
TL;DR
- o3-mini reportedly outperforms o1-mini in reliability, making
39%fewer major mistakes on real-world questions, while delivering24%faster responses than o1 - o3-mini is
63%cheaper than o1-mini and competitive with DeepSeek’s R1 - Developers can choose from three reasoning effort levels (low, medium, high) to balance accuracy vs. speed.
- o3-mini is accessible via ChatGPT and through OpenAI’s API
What sets OpenAI's o3 model apart?
Unlike traditional large language models (LLMs) that rely on simple pattern recognition, the o3 model incorporates a process called "simulated reasoning" (SR), deepening its reasoning capabilities compared to o1.
This allows the model to pause and reflect on its own internal thought processes before responding, mimicking human-like reasoning in a way that previous models like o1 couldn't.
While the o1 models were good at understanding and generating text, the o3 models take it a step further by thinking through problems and planning their responses ahead of time. This "private chain-of-thought" technique is a core feature that sets o3 apart.
Simulated Reasoning gaining popularity
OpenAI's o3 and o3-mini models both uses simulated reasoning (SR), which is gaining traction lately, with Google launching its own Gemini 2.0 Flash Thinking and DeepSeek launching their own models based on this approach.
SR allows AI models to consider their own results and adjust their reasoning as they go, offering a more nuanced and accurate form of problem-solving compared to traditional LLMs.
Simulated reasoning models, including OpenAI's o3, are designed to scale at inference time. This means they can reason and make decisions faster than previous models, offering real-time responses that can handle complex, multi-faceted tasks.
o3-mini is a more adaptive model
OpenAI also unveiled the o3-mini which is more lightweight and has an adaptive thinking time feature, allowing users to select low, medium, or high processing speeds depending on their needs.
The o3-mini is designed for situations where you might not need the full power of o3 but still want to benefit from its advanced reasoning capabilities.
Although smaller and faster, the o3-mini is still powerful. OpenAI claims that it outperforms o1 on several key benchmarks, making it a great option for those seeking more cost-effective performance.
o3-mini vs. deepseek's R1 model
Despite its improvements, o3-mini is not a breakthrough across all benchmarks. While it edges out DeepSeek’s R1 model in select tests like AIME 2024, it lags in others, such as GPQA Diamond for PhD-level science queries.
O3-mini is 63% cheaper than o1-mini and competitive with DeepSeek’s R1.
| Model | Uncached Input Tokens ($/M) | Cached Input Tokens ($/M) | Output Tokens ($/M) |
|---|---|---|---|
| o3-mini | $1.10 | $0.55 | $4.40 |
| DeepSeek R1 | $0.55 | $0.14 | $2.19 |
| o1-mini | $3.00 | $1.50 | $12.00 |
Benchmark Comparison: o3 vs o1
Reasoning Ability
The o3 models are built to simulate reasoning at a deeper level. While o1 could generate responses based on patterns learned during training, o3 actively "thinks" about the problem at hand, improving its ability to tackle complex and multi-step tasks.
Performance Benchmarks
One of the most exciting aspects of o3 is its performance on various benchmarks. For example, it scored 75.7% on the ARC-AGI visual reasoning benchmarkin low-compute scenarios, which is impressive compared to human-level performance (85%). This was a huge improvement over o1 and shows just how much further o3 can go in solving challenging problems.
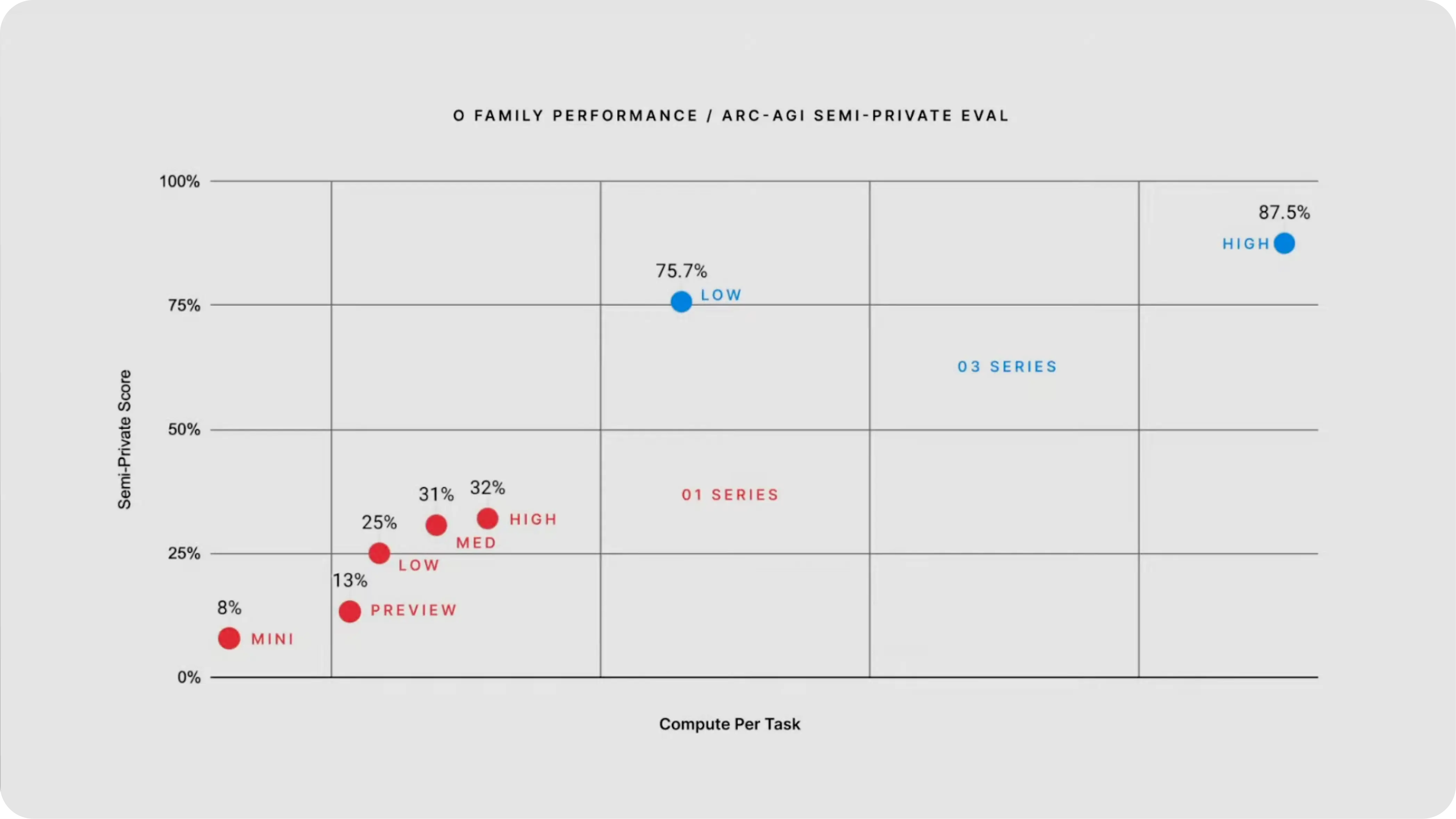
Image source: OpenAI's Youtube announcement
Mathematic and Science
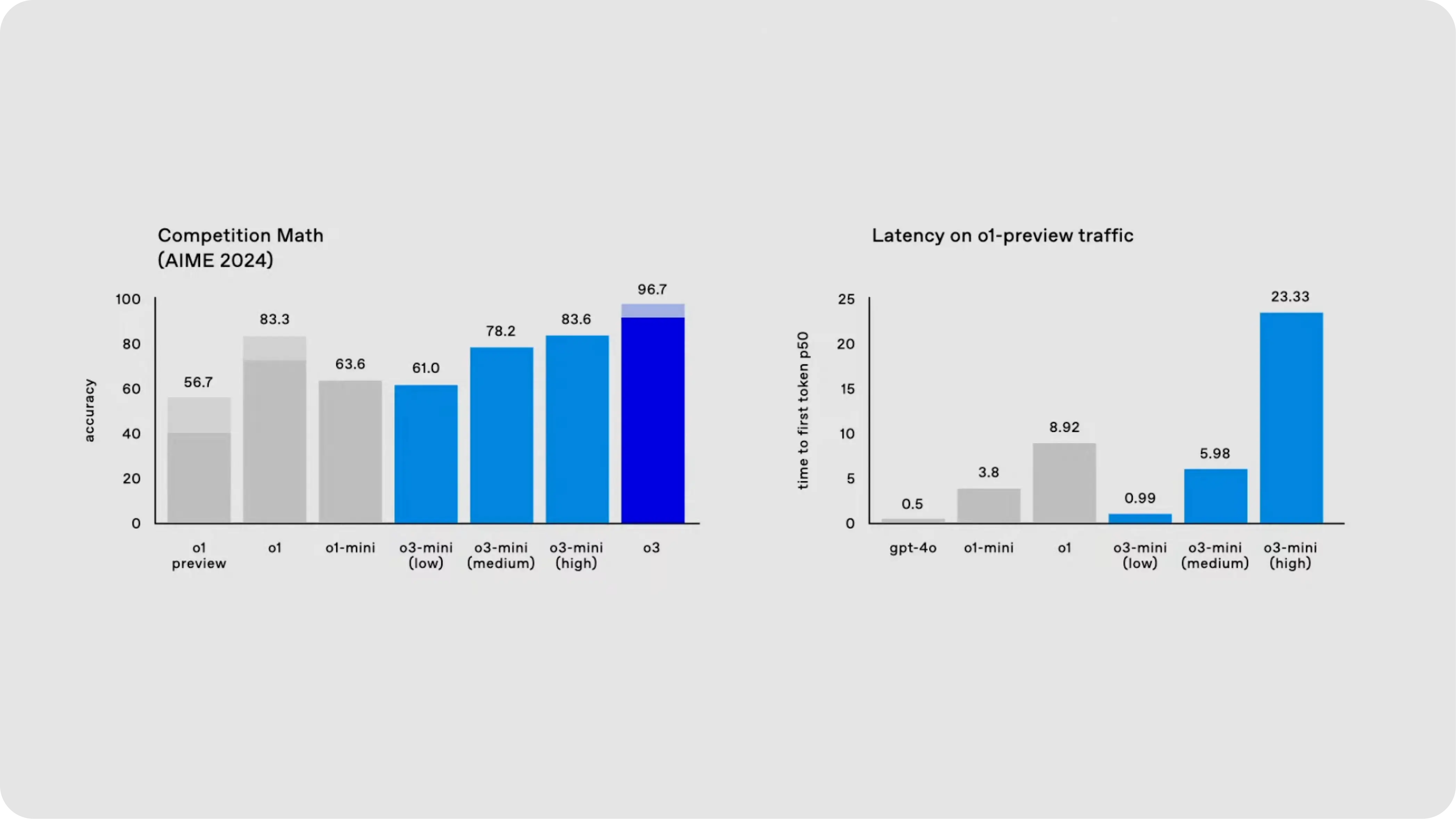
OpenAI reports that o3 also achieved remarkable results in subjects like mathematics and science. For instance, it scored 96.7% on the American Invitational Mathematics Exam and 87.7% on a graduate-level science exam. These scores highlight the model's increased capacity for solving complex problems in fields that require high-level reasoning.
Code and Programming
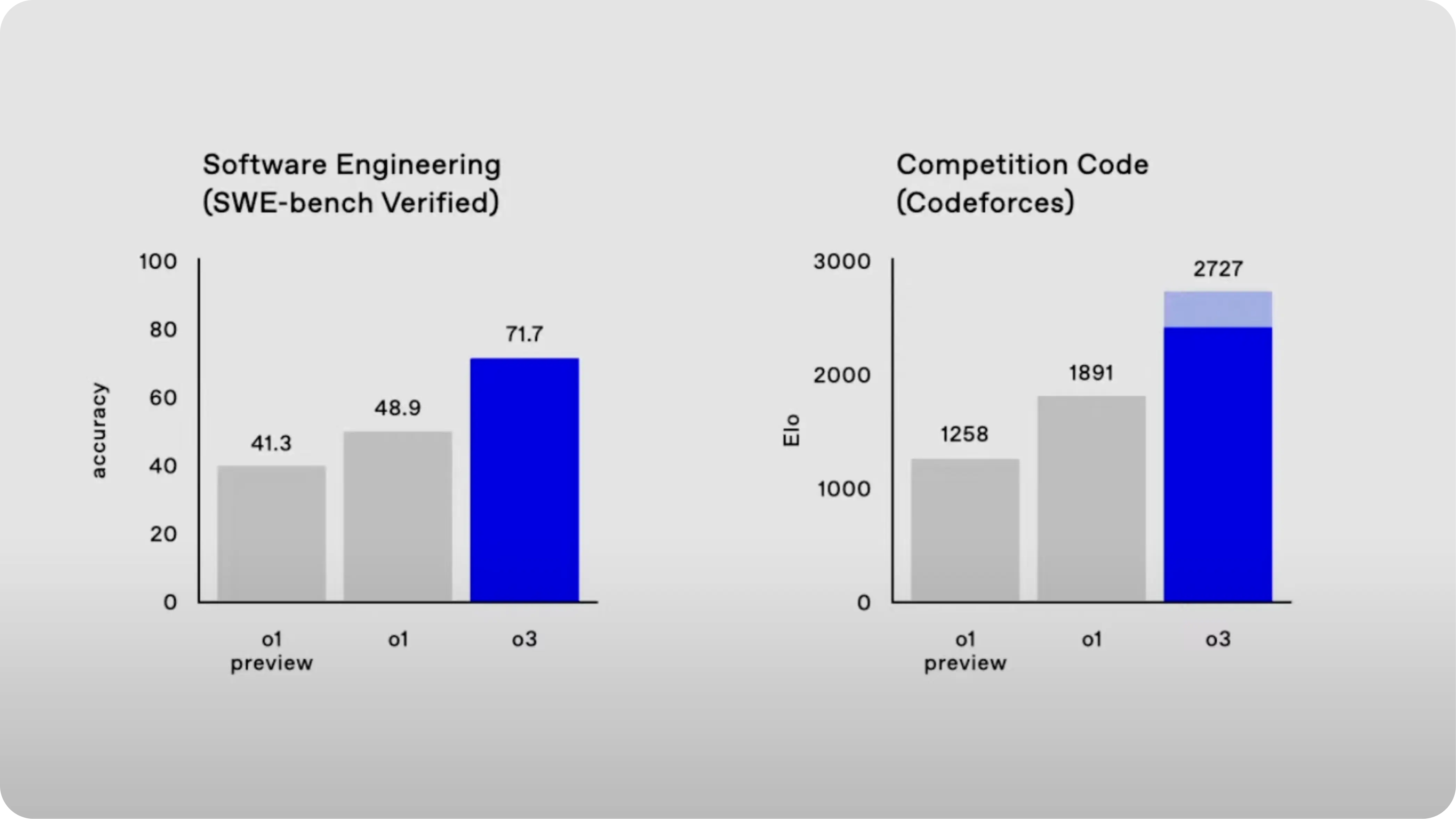
In terms of coding, o3 also outperforms o1. For example, it scored better than o1 on the Codeforces benchmark, which tests the model's ability to solve programming problems. This shows that o3 is more adept at tasks that require logical thinking and problem-solving.
o3's Other Benchmarks
ARC-AGI Benchmark
ARC-AGI tests an AI model's ability to recognize patterns in novel situations and how well it can adapt knowledge to unfamiliar challenges.
- O3 scored
75.7%on low compute - O3 scored
87.5%on high compute, which is comparable to human performance at85%
With 87.5% accuracy in visual reasoning, o3 addresses prior models' struggles with spatial and physical object analysis. This breakthrough enhances real-world applications like robotics, medical imaging, and AR, fueling the AGI conversation. O3’s advancements mark a key step toward smarter, more capable AI systems.
American Invitational Mathematics Exam (AIME)
With an impressive 96.7% accuracy, O3 significantly outperforms O1's 83.3%. This leap showcases O3's superior ability to handle complex tasks. Mathematics, a crucial benchmark, highlights the model's capacity to grasp abstract concepts fundamental to scientific and universal understanding. O3's enhanced accuracy cements its position as a game-changer for users seeking precision and advanced reasoning in AI applications.
GPQA Diamond Benchmark
Scored 87.7%, demonstrating strong reasoning skills in graduate-level biology, physics, and chemistry questions.

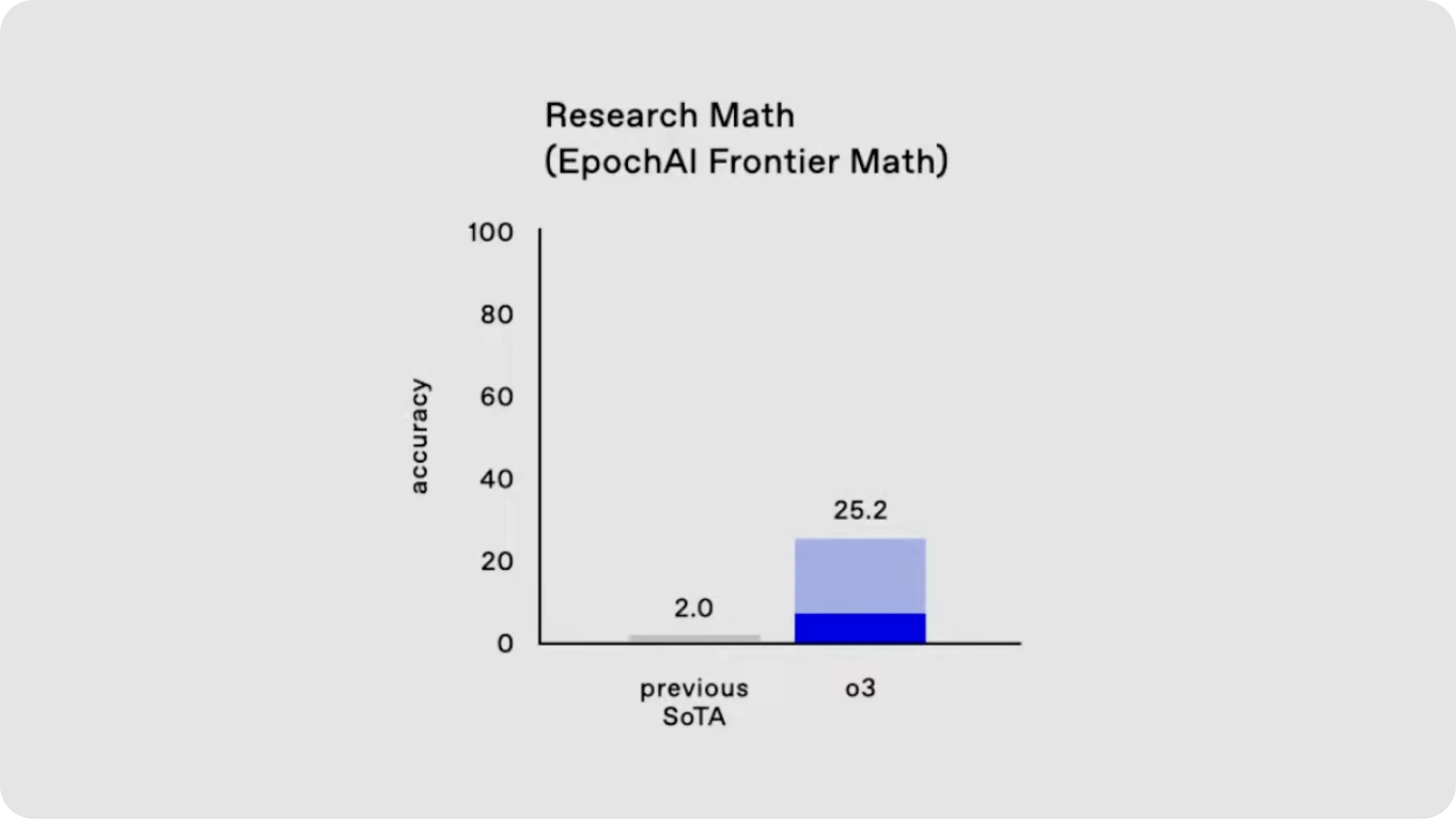
EpochAI Frontier Math Benchmark
The EpochAI Frontier Math benchmark is one of the toughest challenges featuring unpublished, research-level problems that demand advanced reasoning and creativity.
These problems often take professional mathematicians hours or even days to solve. O3 solved 25.2% of the problems, when no other model has exceeded 2% previously on this benchmark.
Why not o2?
Why did OpenAI skip o2? According to OpenAI's CEO, Sam Altman, the decision was purely a matter of avoiding potential trademark issues. The name o2 was not used because it could have clashed with a British telecom company, O2.
So, in the spirit of "OpenAI being really bad at names," Altman humorously explained, the team decided to jump straight to o3 instead. While the name might seem a bit unconventional, the reasoning behind it was purely practical.
How can developers access o3?
- o3-mini is available in the API (Chat Completions, Assistants, and Batch API)
- o3-mini is also available in ChatGPT and will replace o1-mini in the model picker.
Integrate OpenAI o3 with Helicone ⚡️
Integrate LLM observability with a few lines of code. See docs for details.
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: `https://oai.helicone.ai/v1/${HELICONE_API_KEY}/`
});
Bottom Line
The o3 family is a major milestone for OpenAI towards models that can reason and tackle problems in a more human-like way. As simulated reasoning continues to rise in popularity across the industry, it will be exciting to see how o3 and o3-mini influence the future of AI.
In the coming months, we can expect to see more updates on the performance and availability of these groundbreaking models.
Other models you might be interested in:
-
Everything you need to know about OpenAI's o1 and ChatGPT Pro
-
Meta's Llama 3.3 — Benchmarks, features & comparison with GPT-4 or Claude-Sonnet-3.5
-
GPT-5: release date, features & what to expect
Questions or feedback?
Are the information out of date? Please raise an issue or contact us, we'd love to hear from you!