Text Classification with LLMs: Approaches and Evaluation Techniques For Developers
Large Language Models (LLMs) are transforming text classification, making tasks easier for developers. As OpenAI CEO Sam Altman states, "The potential applications of LLMs are limited only by our imagination." In this blog, we’ll guide you through why and how to use LLMs effectively for text classification, specifically approaches such as supervised vs. unsupervised learning, prompt engineering, and fine-tuning.

What You'll Learn
- What is Text Classification With LLMs?
- LLMs vs. Traditional Text Classification
- Popular Models for Text Classification
- Approaches to Text Classification
- Best Practices for Building with LLMs
- Evaluating Text Classification Models
- Challenges and Limitations
What is Text Classification With LLMs?
LLMs excel in tasks like spam filtering, sentiment analysis, and topic detection, achieving high accuracy with minimal setup. These advancements enable developers to address complex NLP challenges efficiently, cementing LLMs as essential tools in modern software development.
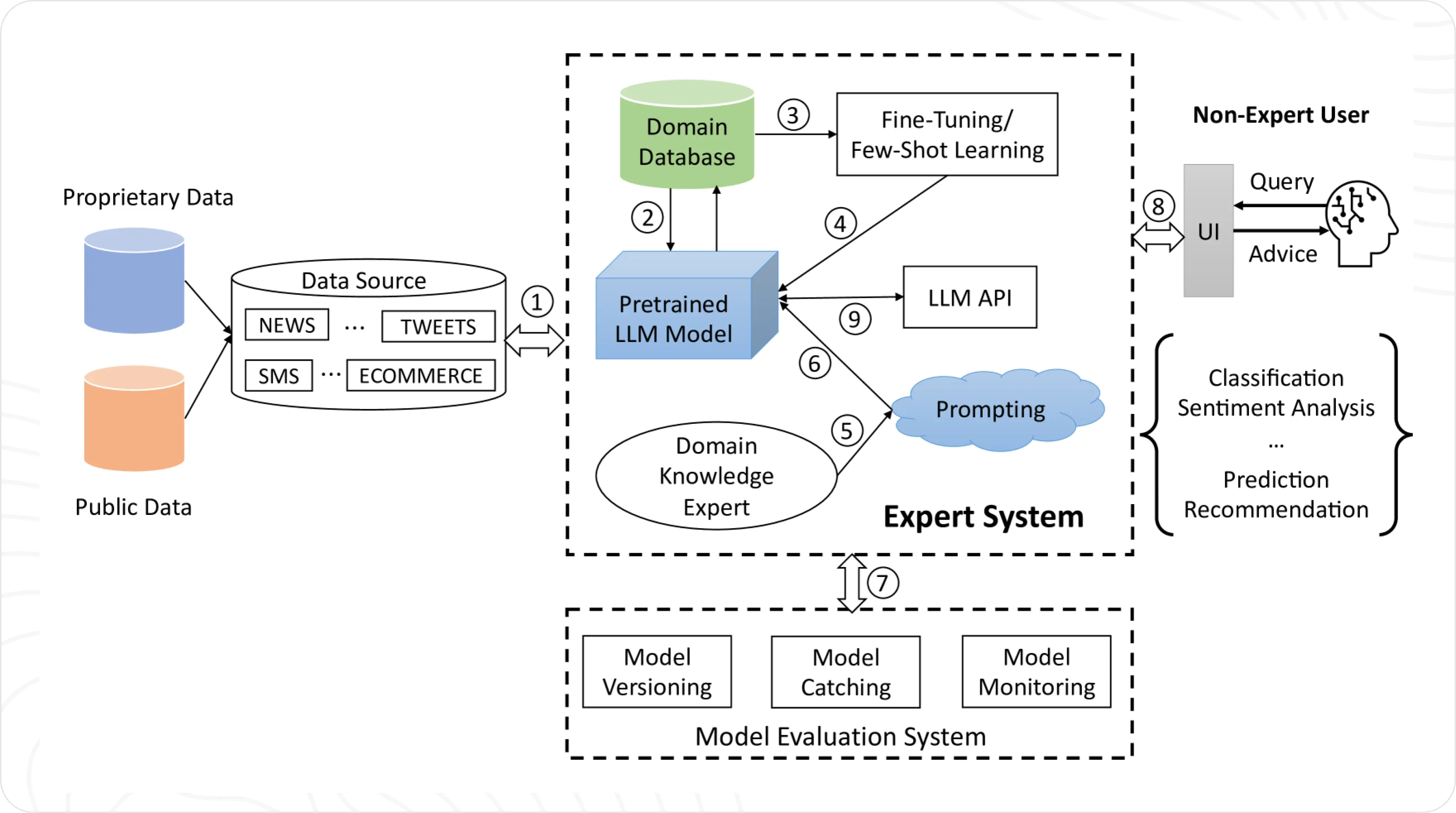
Image source: A sample framework of Text Classifiers
Above is a sample framework proposed in a recent research in Large Language Models as Text Classifiers that demonstrates that LLMs can outperform traditional methods across multiple classification tasks, especially when enhanced with few-shot learning or fine-tuning techniques. This makes them particularly valuable for developers looking to implement robust text classification systems quickly.
LLMs vs. Traditional Text Classification
Text classification with Large Language Models (LLMs) differs from traditional approaches in several ways. While conventional methods often rely on large labeled datasets and fixed features (e.g., n-grams or word embeddings), LLMs can perform zero-shot or few-shot classification by leveraging natural language prompts and pre-trained knowledge—reducing the need for task-specific labels.
Traditional Text Classification Flow
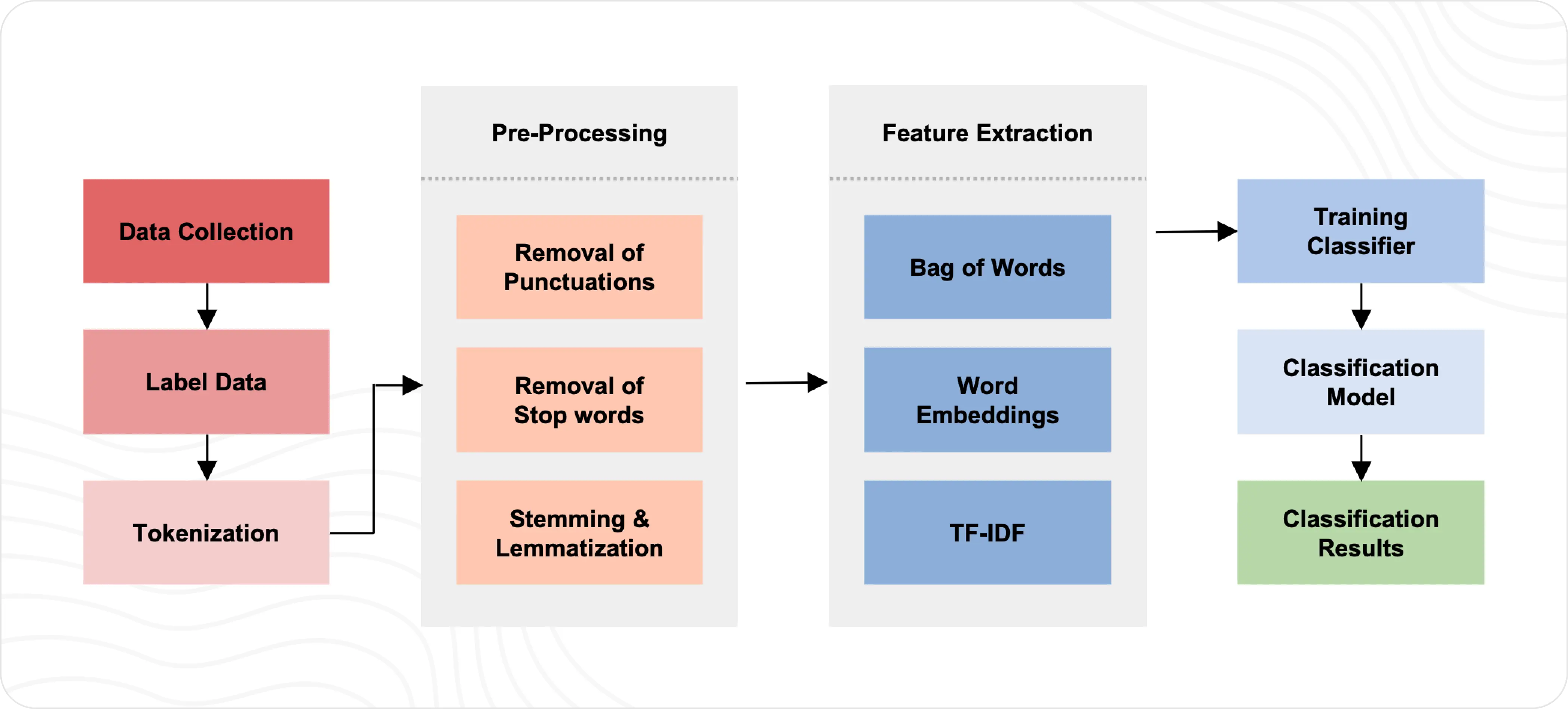
Text Classification with LLMs (Zero-Shot) Simplified Flow

Image source: Large Language Models as Text Classifiers
LLMs also excel at handling complex linguistic nuances (e.g., irony, contrast) and can quickly adapt to new tasks without retraining. However, they are typically more resource-intensive, and smaller fine-tuned or traditional models may still outperform LLMs when dealing with domain-specific tasks or strict computational constraints.
Proven Performance
Research shows LLMs outperform traditional ML models across datasets after minimal training or fine-tuning, consistently leading benchmarks like GLUE and SQuAD.
Popular Models for Text Classification
Large Language Models (LLMs) like GPT, BERT, and RoBERTa have transformed text classification by offering advanced contextual understanding, flexibility, and state-of-the-art performance.
- BERT/RoBERTa: Excellent for fine-grained classification tasks.
- DistilBERT: Lightweight and fast for production. Here's a Hugging Face's guide on Finetune DistilBERT on the IMDb dataset to determine whether a movie review is positive or negative.
- GPT-3.5 and GPT-4: Versatile with few-shot and zero-shot learning.
- Other LLMs: While not specifically designed for classification, they can be fine-tuned or used in few-shot learning scenarios for text classification tasks.
LLM Observability with 1 Line of Code
Monitor LLM usage and costs across providers like Anthropic, Google, and Azure with Helicone's simple 1-line integration. See doc for details.
from openai import OpenAI
client = OpenAI(
api_key=OPENAI_API_KEY,
base_url=f"https://oai.helicone.ai/v1/{HELICONE_API_KEY}/"
)
Start monitoring your LLM app in seconds ⚡️
Join companies like QA Wolf who trust Helicone to track, debug and optimize their agentic workflows.
Approaches to Text Classification
Supervised vs. Unsupervised Learning
There are two main ways to train models for sorting text into categories: supervised learning and unsupervised learning.
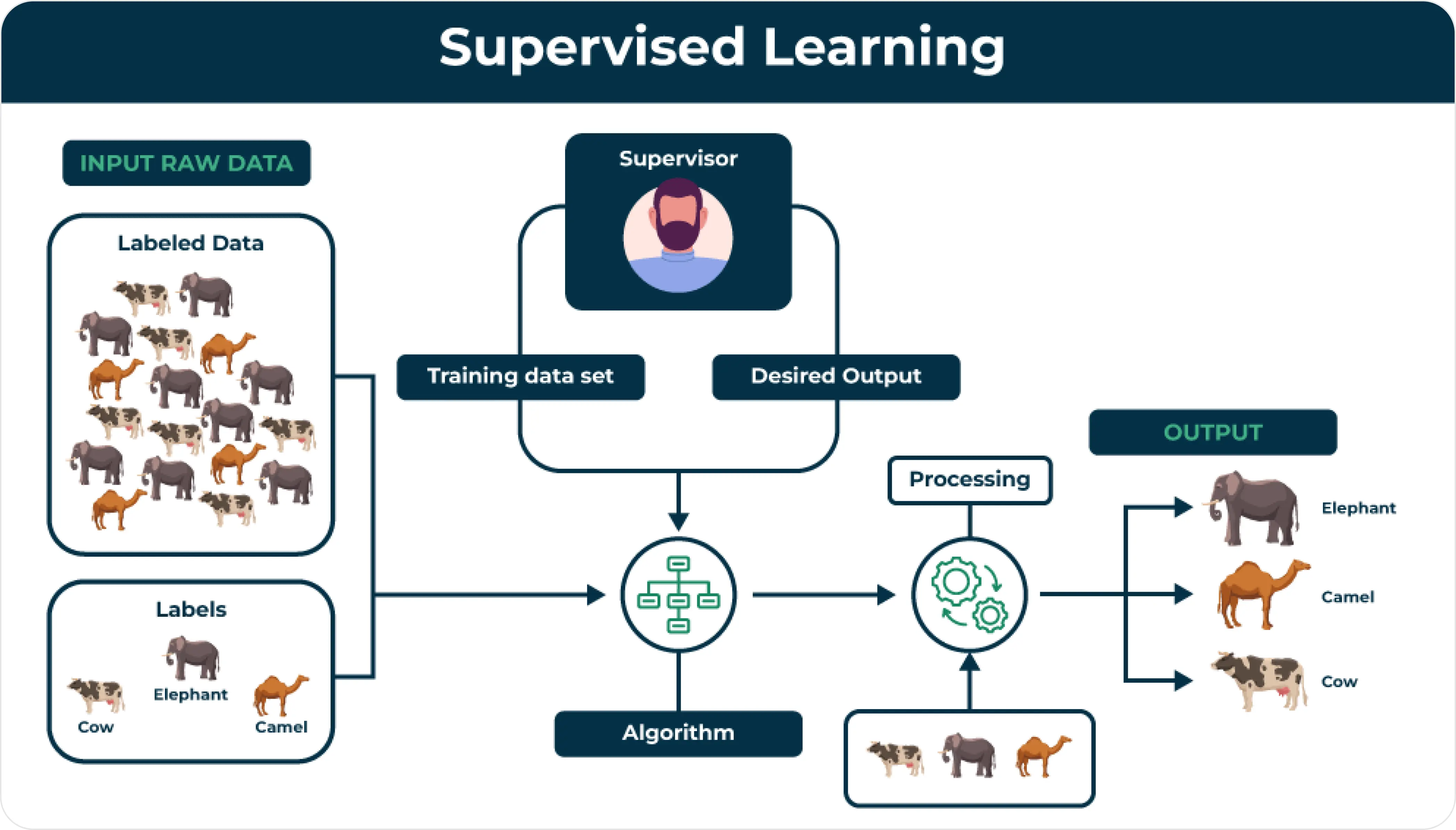
Image source: Supervised and Unsupervised Learning
In supervised learning, models are trained using labeled examples, improving advanced models like BERT and its versions (e.g., DistilBERT, RoBERTa). On the other hand, unsupervised learning skips fine-tuning and relies on prompt engineering to guide models to classify text.
Bottom Line
Both methods have their strengths. Supervised learning works best when you have lots of labeled data, as it can give very accurate results. However, if labeled data is limited, unsupervised learning might be the better option.
Simple Prompt Engineering
Prompt engineering involves crafting and refining prompts to achieve the desired behavior from LLMs. It is an essential step in tasks like sorting information or generating text. For example, if you’ve ever rephrased a question multiple times in ChatGPT, you’ve already practiced something similar to prompt engineering.
Key techniques includes using few-shot or chain-of-thought prompting to improve complex reasoning. Read our detailed guide on key prompt engineering techniques.
Bottom Line
While LLMs offer promising capabilities for text classification, traditional methods and fine-tuned smaller language models can still outperform them in certain scenarios.
Fine-Tuning for Better Performance
Fine-tuning LLMs significantly boosts their performance for specific tasks. For example, ARXIV tested two language models (LLMs) using four datasets, and the results showed clear improvements in how well they classified text.
For instance, the Llama-3-8B(F) model didn’t perform better with COVID-19 tweet sentiments as shown in Table V, but it made a huge leap in spam SMS detection. Its accuracy went from 39% to 98%, transforming it from one of the weakest models to one of the top performers, just behind Qwen-7B(F).
After fine-tuning, the Qwen-7B(F) model consistently improved across all datasets, with accuracy gains ranging from 8.5% to 38.6%. This made it one of the best models for these tasks. These results show that fine-tuning can greatly boost a model’s ability to handle specific text classification challenges.
Best Practices for Building with LLMs
1. Customizing prompts for the model and specific tasks
It's important to craft tailored prompts for your choice of model to make sure it performs well.
For example, when giving examples in few-shot prompting, it's important that they are clear and represent the real-world data. This is especially tricky with customer support tickets, where the language and content can vary a lot.
For details on improving your prompt, check out how to test your LLM prompt.
2. Addressing overfitting and imbalanced datasets
Overfitting occurs when a model performs well on training data but poorly on new or unseen data. This happens when the model learns patterns, noise, or details specific to the training data but not general enough to apply to other data, resulting in poor predictions or inaccurate results.
Techniques like evaluating precision and recall help ensure models generalize effectively. Even if your model shows high accuracy, checking recall and precision helps you understand if the model is too focused on specific examples, especially when you're working with imbalanced datasets.
3. Handling edge cases effectively
Make sure to add explicit instructions and precise prompting to help models handle edge cases, such as distinguishing "known issues" from unresolved tickets.
For example, in ticket management, a ticket should be marked as "resolved" when a vendor confirms it as a known issue, even if the bug still exists. Without clear instructions about this business rule, the model may incorrectly keep these tickets open, not understanding that known issues count as resolved.
Evaluating Text Classification Models
Accuracy
Accuracy measures the percentage of correct LLM predictions. It’s calculated by dividing the number of correct predictions (true positives and true negatives) by the total number of predictions. The formula is:
Accuracy = (True Positives + True Negatives) / (True Positives + True Negatives + False Positives + False Negatives)
F1 Score
F1 Score is a balance between precision and recall, especially for imbalanced datasets. The F1 score is calculated as:
F1 = 2 _ (Precision _ Recall) / (Precision + Recall)
Where:
- Precision measures how many of the predicted positive cases were actually correct.
Precision = True Positives / (True Positives + False Positives) - Recall shows how many actual positive cases the model identified.
Recall = True Positives / (True Positives + False Negatives)
U/E Rate
U/E Rate measures the rate of uncertainty or erroneous outputs. It counts how often the model either refuses to make a prediction or gives an irrelevant answer. The formula is:
U/E = (Uncertain Outputs + Erroneous Outputs) / Total Samples
This metric helps us understand when a model fails to give useful results, unlike traditional models that always give an answer.
Summary of Insights From Experimental Results
The experiment show that fine-tuned models significantly outperform other approaches. Traditional ML algorithms (MNB, LR, RF, DT, KNN) performed poorly on accuracy and F1 scores
Neural networks (NN) performed better, with GRU achieving 69.13% accuracy and 63.33% F1 score. GPT-3.5 outperformed other base LLMs but still fell short of neural networks. Finally, fine-tuned Qwen-7B(F) achieved the best results with 83.88% accuracy and 84.33% F1 score.
This demonstrates that fine-tuning LLMs can provide superior text classification compared to both traditional and neural network approaches.
Challenges and Limitations
Large Language Models (LLMs) perform well in classifying text and analyzing sentiments across different topics, but ARXIV experiments revealed some challenges that limit how practical they are for certain tasks:
- Inconsistent Output Formats: Issues with adhering to structured outputs like JSON.
- Classification Limitations: LLM may struggle with classifying sensitive or complex content.
- Commercial Restrictions: Closed-source APIs have rate limit on requests. Their API costs can add up quickly if you’re handling a lot of data.
- Hardware Requirements: Some LLMs require high-performance computing resources. This can be a roadblock for businesses that don’t have access to expensive computing systems, making it harder to scale their LLM applications.
- Slow Processing Times: Longer latency compared to traditional ML models, but can be more accurate.
Bottom Line
The potential for automating text classification with LLMs is immense, but challenges like high computational costs, API rate limits, and the need for consistent output formats underscore that LLMs aren’t always a plug-and-play solution.
Tools like Helicone can help monitor and analyze prompt usage to optimize performance and cost.
Ready to optimize your LLM app performance? ⚡️
Track, monitor and optimize your LLM app with Helicone's analytics dashboard. Integrate with your favorite LLM providers in seconds.
You might find these useful:
-
Top 10 AI Inferencing Platforms in 2025
-
The Emerging LLM Stack: A New Paradigm in Tech Architecture
-
The Case Against Fine-tuning
Questions or feedback?
Is the information out of date? Please raise an issue and we'd love to hear your insights!